本文以Kaggle新手习题——Titanic: Machine Learning from Disaster为场景开展实验,以此熟悉Kaggle平台。

本文的源码托管于我的Github:Practice-of-Machine-Learning/code/Kaggle_Titanic/,欢迎查看交流。
1.任务概述
Titanic: Machine Learning from Disaster(泰坦尼克之灾)是Kaggle的入门练习题之一。本题要求在所给出的人员相关信息数据基础上,判断其是否在沉船事故中幸存。这是一个典型的二分类问题,这里通过构建决策树分类器实现。本文任务安排如下:
- 数据初探:查看并理解原始特征含义,进行简要的可视化分析以形成初步的数据洞察;
- 特征工程:针对决策树分类器模型,基于对数据的理解,对原始数据进行预处理,构建用于模型训练的特征数据集;
- 决策树分类:训练决策树分类器,得出预测结果,采用预测准确度评价结果好坏并进行改进分析;
2.数据初探
赛题主页介绍了所提供的原始数据集,包括训练集与测试集,均以.csv文件形式给出,包括了乘客ID、年龄、性别、票价等等数据,同时训练集还给出了幸存与否的标签。原始数据的概略信息如下所示:
数据样本数:#train=891,#test=418,基本特征如下表:
| 原始特征名 | 数据类型 | 存在缺失值? | 取值解释 |
|---|---|---|---|
| PassengerId | int | 乘客ID,0,1,2… | |
| Pclass | int | 船舱等级,{1,2,3} | |
| Name | object | (称谓+)姓名,string | |
| Sex | object | 性别,{‘male’,’female’} | |
| Age | float | 有 | 年龄,{min=0.17,max=80} |
| SibSp | int | 兄弟姐妹同船人数,0,1,2… | |
| Parch | int | 父母孩子同船人数,0,1,2… | |
| Ticket | object | 船票编号(字母数字符号组合,如) | |
| Fare | float | 有 | 票价{min=0,max=512.3} |
| Cabin | object | 有 | 房号,字母+数字 |
| Embarked | object | 登船地,{‘C’,’Q’,’S’} |
结合铁达尼号事件背景,我们可以先对特征与结果的关联性进行猜测,如:上层乘客易幸存(如Pclass=1,房号位于甲板上层,Fare较大等),女性和孩子易幸存(如Sex=’female’,Age较小等)。下图展示了部分特征与结果的关联性:
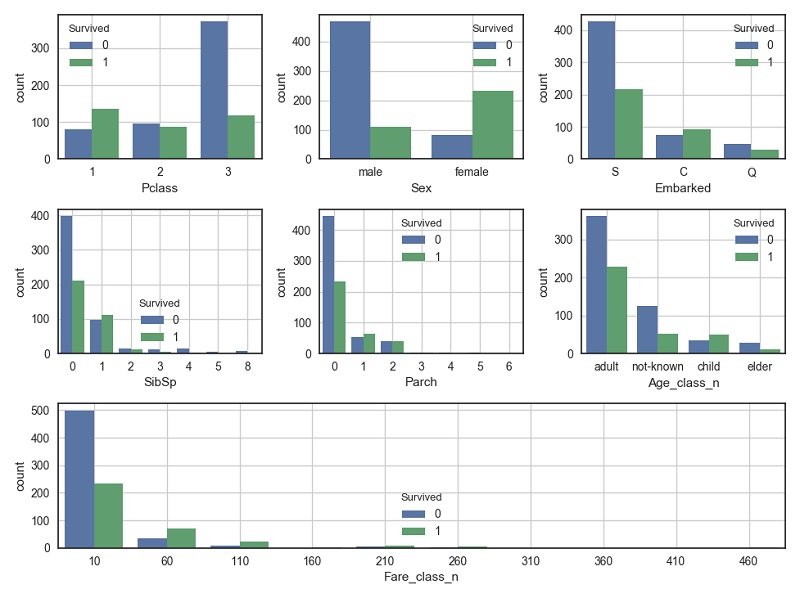
从上图可以验证我们的猜想,如富人(Pclass=1,Fare较大)幸存比例较大,women and children first原则在紧急时刻依然得到了很好的遵循。此外,还可以发现:于C地(法国-瑟堡)登船的乘客幸存比例较高,有亲人同行更容易幸存(许是互帮互助)等等。
3.特征工程
对数据初探的基础上,我们很自然的想到采用决策树模型来进行分类预测,为了使数据能够满足树模型规约化要求,这里对特征进行简单地转换与重构,生成初步用于训练及测试的特征集,列表如下:
| 新特征名 | 解释 |
|---|---|
| Pclass | 船舱等级,val∈{1,2,3} |
| Sex | 性别,val∈{0,1},0~男性,1~女性 |
| Age | 年龄,val∈{-1,0,1,2,3,4},-1~未知,0-4~年龄分级 |
| Fare | 票价,val∈{-1,0,1,2,3},-1~未知,0-3~票价分级 |
| Embarked | 登船地,val∈{-1,0,1,2},-1~未知,0~S,1~C,2~Q |
| IsAlone | 独行?val∈{0,1},0~有亲人做伴,1~独行 |
采用此生成特征数据集(训练集+测试集),均为int型数值,如下图所示(训练集):
PassengerId Survived Pclass Sex Age Fare Embarked IsAlone
1 0 3 1 1 0 0 0
2 1 1 0 2 2 1 0
3 1 3 0 1 0 0 1
4 1 1 0 2 2 0 0
5 0 3 1 2 0 0 1
4.决策树分类
接下来,进行决策树分类实验,包括模型的构建、训练与调优、测试三步骤。为防止决策树过拟合,这里我们以树深max_depth超参数为例,采用交叉验证进行最佳模型的选取。
设定max_depth参数的取值范围,采用10-folds交叉验证获取每个max_depth取值下的决策树模型验证准确度(accuracy),得出准确度随max_depth取值变化如下图示(得出max_depth最优取3):
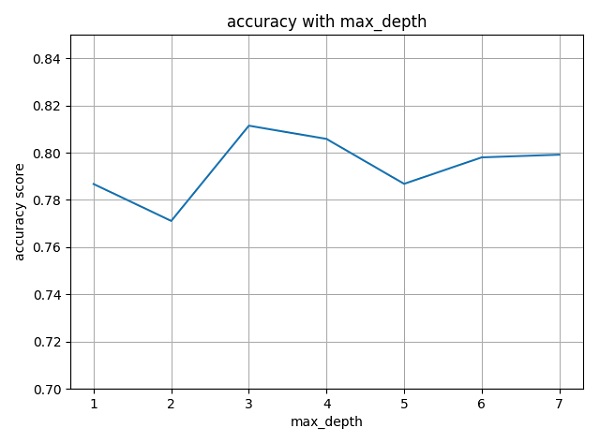
构建最佳max_depth对应的决策树模型(基于基尼纯度),在测试集上进行预测,得出提交文件上传至Kaggle,得出accuracy评分Score=0.77990(并非很理想的结果^-^)。
5.小结
本文简述了采用决策树分类器完成Kaggle入门赛题Titanic的过程,取得了一定的结果,进一步分析可以看出,训练集得分score_train≈0.8,而测试集结果得分score_test≈0.78,这说明,当前决策树模型在平衡泛化能力时(max_depth=3),面临着拟合不足的缺陷,这也是单个树模型所易出现的问题。为提高精度,一方面,做细特征工程,如构建更加丰富的衍生特征或高维组合特征。另一方面,采用学习能力更强的模型,如随机森林,GBDT等来处理当前任务。